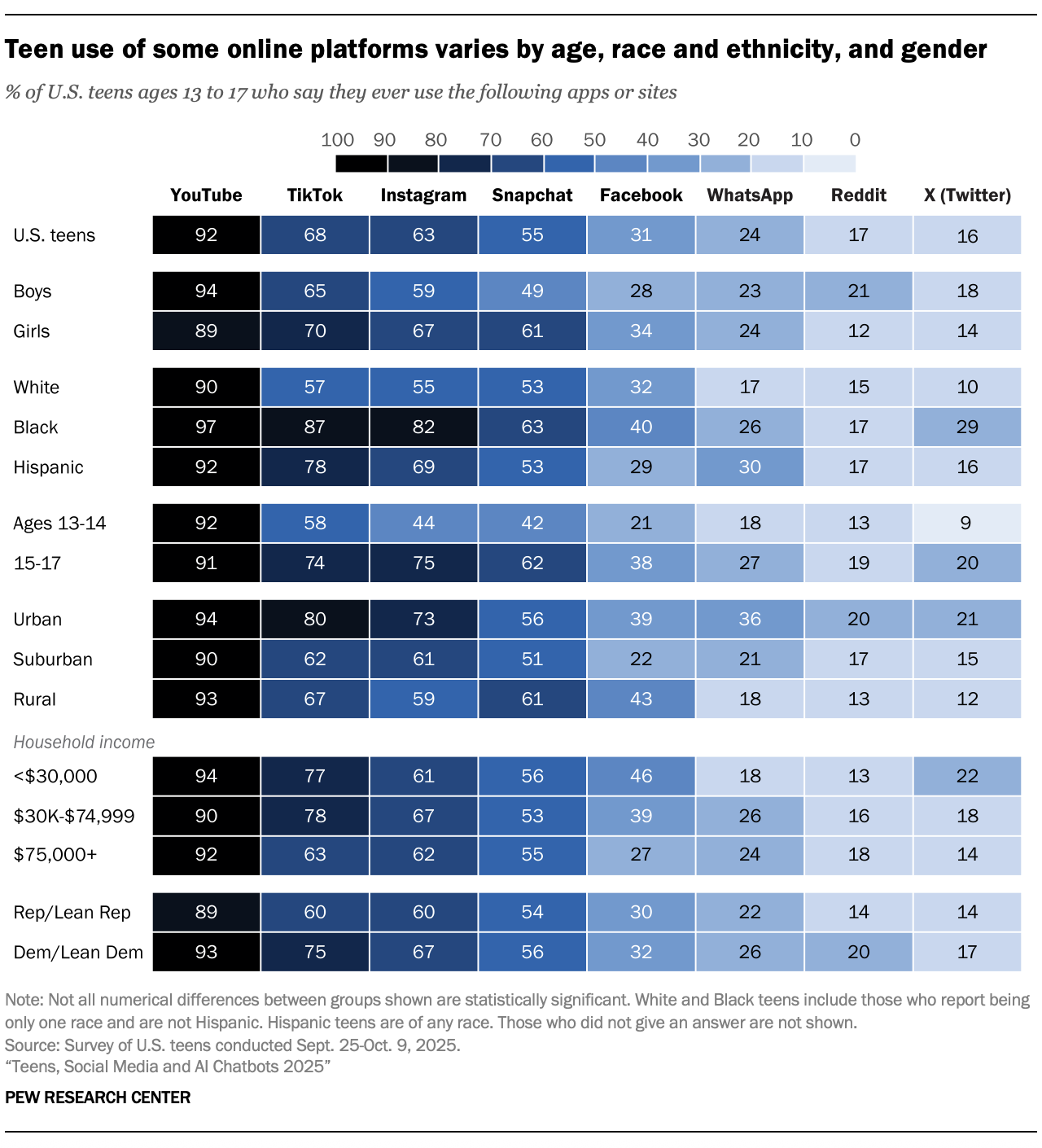
Young people turn to a variety of platforms, but YouTube stands out for being used by nearly all teens. Roughly nine-in-ten report ever using it.
Teens widely use three other platforms:
About six-in-ten or more say they use TikTok and Instagram.
A somewhat smaller share say they go on Snapchat (55%).
Fewer use Facebook (31%) and WhatsApp (24%). And no more than about one-in-five say the same of Reddit or X (formerly Twitter).
[Clip]
Online platform use by demographic groups
Teen use of specific online platforms varies across demographic groups – including when it comes to gender, race and ethnicity, age and household income.
By gender
Teen girls are more likely to use Snapchat and Instagram. For example, 61% of girls say they use Snapchat, compared with 49% of boys.
Meanwhile, boys are more likely to use Reddit (21% vs. 12%) and YouTube (94% vs. 89%).
By race and ethnicity
There are differences in use by race and ethnicity across all the platforms asked about except Reddit. Black teens are more likely than their White or Hispanic peers to use Instagram, TikTok, X, Snapchat and YouTube. For example, 82% of Black teens say they use Instagram. This drops to 69% among Hispanic teens and is even lower for White teens (55%). And Black teens are more likely than Hispanic teens to use Facebook.1
WhatsApp is used by a larger share of Hispanic and Black teens than White teens.
By age
Older teens stand out from younger teens in using nearly every platform we ask about. For instance, three-quarters of 15- to 17-year-olds say they use Instagram, compared with 44% of 13- to 14-year-olds.
YouTube is the only site measured that older and younger teens are equally likely to use.
By household income
Teens in households with lower and middle incomes are more commonly using TikTok and Facebook, a largely similar pattern to previous years.
For instance, 46% of teens living in households earning less than $30,000 a year say they use Facebook. Similarly, 39% of those in households with incomes between $30,000 and $74,999 say the same. However, this drops to 27% among teens in households earning $75,000 or more.
By party
In a pattern seen in previous Center surveys, a larger share of teens who identify as Democrats than Republicans say they use TikTok, Instagram, Reddit and YouTube.
For example, there is a large partisan gap for TikTok: 75% of Democratic and Democratic-leaning teens say they use TikTok, compared with 60% of Republicans and Republican leaners.
[Clip]
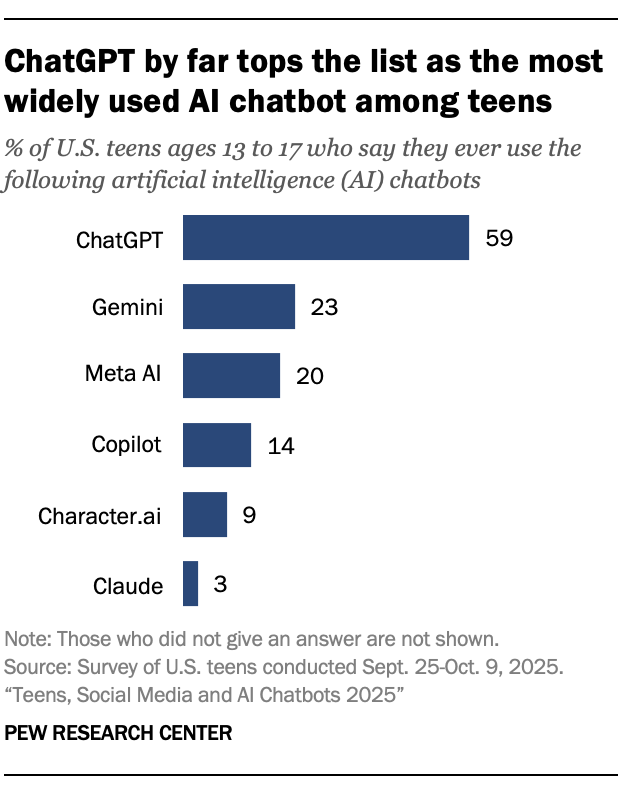
Which chatbots do teens use?
In addition to understanding their overall use, we also asked teens about their use of six specific chatbots.
ChatGPT (59%) is by far the most widely used chatbot and the only one we measured that a majority of teens use.
This is more than twice the rate of the next most commonly used chatbots: Gemini (23%) and Meta AI (20%).
Fewer say they use Copilot,Character.ai and Claude.
By race and ethnicity
Black and Hispanic teens are more likely than their White peers to say they use Gemini and Meta AI.
Black and White teens differ modestly in their use of ChatGPT and Character.ai.
There are no significant differences in use for Copilot or Claude.By age
Teens ages 15 to 17 are more likely than those 13 to 15 to report using ChatGPT and Meta AI.
By household income
ChatGPT use is more common among teens in higher-income households. About six-in-ten teens living in households earning $75,000 or more (62%) say they use it. That compares with 52% of teens living in households earning less than $75,000.
Meanwhile, lower- and middle-income teens are more likely to use Character.ai. Some 14% of teens in households with incomes of less than $75,000 report using it. This is double the rate among teens in households with incomes of $75,000 or more (7%).
Generative AI tools are becoming increasingly capable at helping people organize, analyze, and make sense of complex information. For many performing arts organizations, low-cost AI-powered tools...
As many of you know, our Advisory Committee has been building some best practice guidance for generative and agentic AI usage metrics. Today we’re sharing the results of that work with you.
The challenge
We developed Release 5.1 of the Code of Practice before to the public availability of generative and agentic artificial intelligence. In this consultation we have built on the patterns in the Code to create mechanisms for reporting on this new type of usage. The new guidelines mostly apply to AI tools on publisher platforms. Third-party and off-site tools like ChatGPT, Consensus or Perplexity may also find the guidelines useful, particularly in conjunction with our existing Syndicated Usage best practice.
We want to make sure that the new guidelines work for as many people as possible, so we really want to hear from you. Whether you are a technology provider, a publisher, a librarian or a consortium manager, please send us your feedback!
The creation of an Artists’ Resale Right has been adopted in many countries to at best mixed reviews. They’re unsurprisingly widely supported by potential beneficiaries, but the data on who actually benefits raises real questions about the wisdom of the policy. Canada may be headed in the same policy direction as the government recently announced in its budget plans to introduce the measure. Professor Guy Rub is the Vincent J. Marella Professor of Law at Temple University’s Beasley School of Law and an expert in the intersection between intellectual property law, commercial law, the arts, and economic theory. Professor Rub has written critically about the Artists’ Resale Right including as part of a submission to a House of Commons committee that studied the issue several years ago. He joins the Law Bytes podcast to discuss the policy measure and its drawbacks, including his view that it primarily benefits artists who are wealthy, old, or dead.
Title: Indological Knowledge and its Syllogism Authors: Asundi, A. Y.; Karisiddappa, C.R. Abstract: The study of ancient and medieval history, culture, customs, art and science, languages and socio-economic knowledge of India is known as Indology. Ranganathan proposes Indology as an area study with above features. Indological knowledge system is vast and encompasses many areas of study, contrary to the knowledge systems of the West. Bacon, Kant, Hegel and Pearson identified only two or three categories of knowledge of their times, while the ancient Indian sources have enlisted as many as 64 Vidyas. The knowledge treasure of India made the foreign traveller Huen Tsang take back loads of writings on return home. Not speaking about 4 Vedas, 112 Upanishads, 6 Vedangas, Shastras and 18 Puranas which are still referred to as cues and that depict the holistic horizon of India’s knowledge treasure. Max Muller a German scholar compiled 50 books entitled “Sacred Works of the East”. A living example of one of India’s famous treatise, is the ‘Kautilya’s Arthasastra’ which dates back to 2nd Century BCE the MSS available in the Oriental Research Institute, Mysore was translated into English by Shamasastry, the then Curator of the Institute. One of the well known Oriental historian Basham lists 11 areas of knowledge attributed to well known Indian scholars like Aryabhata and Panini. The paper examines the vast knowledge treasure of India nested in Vedas and other numerous sources of the times immemorial. It primarily desires to focus more on the aspects of Space and Time knowledge and their implications in knowledge organisation. Page(s): 343-348
Title: A Critical Review on the Treasure of Indian Knowledge available in various Scriptures in relevance to Modern Era Authors: Arora, Dr. Smita Abstract: Indian knowledge system is a rich legacy catering the society with the concepts of holistic way of living with high levels of spiritual consciousness. The Vedas, Upnishad, Aranyaka, Brahmanas and various other epics are great repository of knowledge encompassing every walk of life, like science, technology, astronomy, architecture, mathematics, ecology and agriculture etc. Though we are presently living in an era of Artificial Intelligence, the wisdom of our ancient Vedic era can't be denied in current scenario. The present era achievements can be denoted as the fruits which the tree of time is bearing and whose roots can be traced in our ancient literature.Therefore, it becomes essential to explore the hidden treasure of Indian knowledge present in the Vedic era or ancient times which have been described in various scriptures, manuscripts, epics and texts etc. The earliest sources of our knowledge of Indian philosophy and medicine are the four Vedas, few sacred books of knowledge which were available from the period of 1500 to 800 B.C. This research article provides a critical review of the concepts and knowledge which our ancient scholars possessed and that have been adopted in the modern era after conducting scientific researches. This study serves as an initial step to peep into the ancient era window using a spectacle of modern era concepts. Page(s): 349-358
Title: A Critical Study on Vāda, Jalpa, and Vitandā in the Mahābhārata and Contemporary Legal Discourse Authors: Jyoti, Dr.; Kumar, Dr. Asheesh; Pattanaik, Jyoti; Tripathi, Dr. Manorama Abstract: The Nyāya Sūtras of Maharshi Gautama introduced the concept of "Kathātraya," comprising Vāda (a debate for truth-seeking without any intention of triumph or defeat), Jalpa (a debate aimed at victory with argumentative discourse for establishing one’s own viewpoint and vanquishing the opposition, akin to contemporary legal battles), and Vitandā (a debate solely for refuting the opponent’s argument without presenting an alternative viewpoint ), which reflects various aspects of parliamentary discussions and judicial discourse. These forms of dialogue find significant parallels in modern parliamentary debates and legal proceedings. The present study has examined cases like the death penalty debate and Sabarimala judgment through the Kathātraya lens by taking incidents described in Mahabharata. In tune with the NEP 2020, it has highlighted the integration of Indian Knowledge Systems (IKS) into contemporary law and education, emphasizing linguistic and cultural preservation. It has connected ancient philosophical doctrines with modern Sustainable Development Goals, illustrating how ancient Indian philosophical doctrines can improve contemporary policy-making debates. It has spotlighted the profound ethical wisdom which is embedded in India’s rich intellectual heritage. Page(s): 359-369
Title: Plant Cultivation and Indian Knowledge System: An Exploration of the Available Scholarly Literature Authors: Das, Moumita Abstract: The interest in the traditional practices of plant cultivation has gained momentum in India in the past few decades. We are witnessing a revival of ancient concepts, such as Vrikshayurveda. The underlying reasons of this resurgence could be attributed to the modern unsustainable cultivation practices resulting in the increasingly depleting soil quality of the farmlands, low nutritional value of the produce, indiscriminate exploitation of the forest resources, water pollution caused by chemical fertilisers and pesticides, and the consequent diseases posed to human and animal life, to name a few. Needless to say, all these disturbing issues pose a high threat to not only our food security but also to our very existence on this planet. Meanwhile, India is poised to be a completely developed nation by 2047 as envisioned by the sentiment of Viksit Bharat@2047. Clearly, to enable Bharat to be completely developed by that time, appropriate ground-breaking interventions need to be undertaken from today itself to mitigate the existing problems. The scientific community in India is now actively looking for solutions to these problems in the Indian Knowledge System (IKS). Lately there has been an impetus in the research carried out by universities and institutions on the feasibility of plant cultivation that is based on the IKS. The Government of India has also been supportive in this regard with several Ministries, such as the Ministry of AYUSH and Ministry of Agriculture paying special attention to the development of innovative solutions towards sustainable plant cultivation practices. In this regard, a considerable amount of work has been done by researchers and scientists in mining the knowledge available in the IKS and practicing them. However, it is felt that the information available to us regarding IKS for plant cultivation is still growing and there is a considerable scope for continued research on exploring IKS, especially that available in regional languages. This study is exploratory research on the available literature on plant cultivation practices and the IKS. This paper attempts not only to explain the various types of plant cultivation practices as mentioned in the IKS but also to highlight the available literature on the modern scientific experiments and innovations that provide the evidence of the efficacy of the IKS-based plant cultivation techniques. The collated and updated literature presented in this paper is expected to assist the researchers and policy makers to take an informed decision on the adoption of best practices in plant cultivation using IKS. The study is also expected to provide insight into the design, development and offering of customised referral services in IKS-based resources on plant cultivation by the libraries. Page(s): 370-380
Brahma's Dreamby Shree Ghatage was a book I snatched out of a pile of stuff my sister was giving away last year, but she'd never gotten around to reading it herself, so she couldn't give me a preview. Brahma's Dream is set in India just before it gains self-rule, and concerns the family of Mohini, a child whose serious illness dominates her life.
This is one of those middle-of-the-road books that was neither amazingly good nor offensively bad, and therefore I struggle to come up with much to say about it. That makes it sound bad, but it isn't--I enjoyed my time with it. I thought Ghatage did a good job with exploring life on the precipice of great political change, although the history and politics of 1940s India is more backdrop to the family drama than central to the story. I liked Mohini and her family; because the nature of her illness necessitates a lot of rest and down time, Mohini is naturally a thoughtful child, as her thoughts are sometimes all she has to amuse herself. However, she never crosses the line into being precocious, which was a relief.
Neither did I feel like the book leaned too hard on Mohini's illness to elicit sentimentality from the reader. Obviously, an illness like hers is the biggest influence on her life, and on the lives of her immediate family, and there are many moments you sympathize with her because she can't just be a child the way she wants to be, but I didn't feel like Ghatage was plucking heartstrings just for the sake of it.
Reading the relationships between Mohini and her family was heartwarming, especially with her grandfather, who takes great joy in Mohini's intellect and is often there to discuss the import of various societal events with her.
Ghatage's descriptive writing really brings to life the India of the time, with the colors, smells, sounds, and sights that are a part of Mohini's every day.
It reminded me of another book I read about a significant event in Indian history (the separation of India and Pakistan) told through the perspective of a young ill girl, Cracking India.
On the whole, this was a sweet, heartfelt book. It's not heavy on plot, but if you enjoy watching the story of a family unfold and the little dramas that play out, it's enjoyable.
This article examines the differences in diversity, equity and inclusion (DEI) efforts between library collection development and archival practices, highlighting the unique challenges faced by archives, including dark archives, in achieving inclusive and balanced collections. The article also includes a case study describing the coverage audit performed by CLOCKSS in order to uncover areas where further development is needed in order to advance DEI in its archiving practices.
This article examines the differences in diversity, equity and inclusion (DEI) efforts between library collection development and archival practices, highlighting the unique challenges faced by archives, including dark archives, in achieving inclusive and balanced collections. The article also includes a case study describing the coverage audit performed by CLOCKSS in order to uncover areas where further development is needed in order to advance DEI in its archiving practices.
This article examines the differences in diversity, equity and inclusion (DEI) efforts between library collection development and archival practices, highlighting the unique challenges faced by archives, including dark archives, in achieving inclusive and balanced collections. The article also includes a case study describing the coverage audit performed by CLOCKSS in order to uncover areas where further development is needed in order to advance DEI in its archiving practices.
The Quebec government has amended its Internet streaming legislation by removing an exemption for social media services, establishing the most unworkable social media regulation in the world with companies required to meet both French language minimum content quotas and discoverability requirements for user content. I previously argued that Bill 109, which has now completed its clause-by-clause review, is unconstitutional, unnecessary, and unworkable. If enacted into law, it is sure to face a constitutional challenge and the prospect that streaming services such as Netflix and Spotify will either block the Quebec market or be forced to remove considerable English and foreign language content in order to comply. The result will mean less choice for Quebec-based subscribers without any requirements for more Quebec content (the law applies to French language content, not Quebec-based content).
Incredibly, the government, led on the file by Minister of Culture and Communications Mathieu Lacombe, has managed to make an awful bill even worse. During the clause-by-clause review, it approved several changes that establish a virtually unlimited regulatory scope. For example, the original Bill 109 covered:
every digital platform that offers a service for viewing audiovisual content online or listening to music, audio books or podcasts online or that provides access to such a service offered by a third-party platform as well as every digital platform that offers services enabling access to online cultural content determined by government regulation.
Just in case something might still fall through the cracks, the government has amended this provision by replacing “audio books or podcasts online” to “or other audio content.”. In other words, it wants to ensure that any service offering audio or video in whatever digital form now or in the distant future is subject to regulation with French language quotas.
Further, Bill 109’s previous exception for social media has now been removed. The Bill originally stated at Section 3 that “this Act does not apply to social media and digital platforms whose main purpose is to offer Indigenous content.” It also featured a definition for social media as a “digital platform whose main purpose is to allow users to share content and interact with that content and other users.” During clause-by-clause, the government removed the reference to social media in the Section 3 exemption and deleted the social media definition altogether. Lacombe told the committee that it isn’t currently his intent to regulate social media users but that the Quebec government wants to leave open the door to potential regulation if services offer audio or video services. It goes without saying that many social media services already do.
What kind of regulation does the government have in mind?
In addition to registration requirements, the government is establishing discoverability requirements that feature two components: minimum French language content quotas and efforts to make that content easier to discover. The specific percentage for language content quotas would be established by regulation. Lacombe made it clear that both are essential aspects of discoverability: it needs to be easier to discover French language content and there needs to be a minimum percentage of French language content to find.
For curated content services such as Netflix, these requirements are ill-advised by presumably doable. The company already offers easy search functionality for French language content and offers translation into French of thousands of its titles. If the content quotas are too high, the company could exit the market or attempt to meet the obligation by removing content in other languages. Reduced English and foreign language content would help increase the relative percentage of French language content even if the actual amount of it in the catalogue remains unchanged. The same would be true for an audiobook service such as Audible, which might remove titles from its catalogue in Quebec. The likely effect will therefore be reduced choice for Quebec-based subscribers.
But reduced user choice on Netflix and Audible are the best-case scenarios for Bill 109. For services such as Spotify, much of their content is posted by users, whether podcasters or musicians. Meeting a minimum percentage of French language podcasts is seemingly unworkable, since the service doesn’t actually select what podcasts are available on the platform. To meet the legal requirements, it could be forced to block English or foreign language musicians or podcasters to meet the required percentage. The result would be less choice and arbitrary removal of content, including user generated content.
The law has been made worse yet with the inclusion of social media regulation. It is not clear how Facebook, Instagram, TikTok, or Twitter (X) – all of which easily meet the current requirement of “offering a service for viewing audiovisual content online or listening to music” – would meet minimum language content requirements when virtually all of the content found on the platform comes from users. For example, TikTok could display more French language videos to its users but how does it ensure that the total percentage of videos on the entire platform meets a minimum French language quota? These companies do not post or curate the content but would be forced to intervene to somehow meet a minimum French language content requirement.
Lacombe has left himself an out by leaving the specific content quotas to regulation and including provisions that permit the government to strike private deals with individual services (Canadians know how well that worked out with the Online News Act). But the starting point for regulation or negotiation may leave some companies ready to walk away from the province altogether. As far as I can tell, there is no jurisdiction anywhere that has tried to regulate social media content by establishing minimum language quotas for content posted by users. And for good reason: it creates an unconstitutional mess that may give Lacombe and Quebec the distinction of having created the world’s most unworkable and ill-advised attempt at Internet regulation.
Book # (checks notes) 13! From the "Women in Translation" rec list has been The Sunset Years of Agnes Sharp by Leonie Swann, translated from German by Amy Bojang. This book concerns a house full of elderly retirees who end up investigating a series of murders in their sleepy English town.
This book was truly a delight from start to finish. I loved Swann's quirky senior cast; they were both entertaining and raised valid and very human questions about what aging with dignity means. It did a fabulous job scratching my itch for an exciting novel with no twenty-somethings to be seen. Now Agnes, the protagonist, and her friends are quite old, which impacts their lives in significant ways. However, I felt Swann did a good job of showing the limitations of an aging body--unless she's really in a hurry, Agnes will usually opt to take the stair lift down from the second floor, for instance--without sacrificing the depth and complexity of her characters, or relegating such things merely to the youth of their pasts.
The premise of this book caught my attention immediately, but after a lifetime of books with riveting premises that dismally fail to deliver, I was still wary. I'm happy to report that The Sunset Years of Agnes Sharp fully delivers on its promise! Swann makes ample and engaging use of her premise.
The story itself is not especially surprising; if you're looking for a real brain-bender of a mystery or a book of shocking plot twists, this is not it. But I enjoyed it, and I thought Swann walked an enjoyable line between laying down enough clues that I could see the writing on the wall at some point, without giving the game away too quickly. There are no last-minute ass-pulls of heretofore unmentioned characters suddenly confessing to the crime here! The main red herring that gets tossed in the reader is likely to see for what it is very quickly, but for plot-relevant reasons I won't mention here, it's very believable that Agnes does not see that.
Agnes herself was a wonderful protagonist; I really enjoyed getting to go along on this adventure with her. She had a hard enough time wrangling her household of easily-distracted seniors even before the murders started! But the whole cast was endearing, if also all obnoxious in their own way after decades of settling on their own way of getting through life.
Bojang does a flawless job with the translation; she really captures various English voices both in the dialogue and in Agnes' narration. The writing flows naturally without ever coming off stilted or awkward.
I really had fun with this one, and I'm delighted to here there's apparently a sequel--Agnes Sharp and the Trip of a Lifetime--which I will definitely be checking out.
How, whether, and how much publishers will be compensated are some of the major existential questions facing the news industry in the “AI era.” Today, the Tow Center for Digital Journalism is releasing a tracker that monitors developments between news publishers and AI companies—including lawsuits, deals, and grants—based on publicly available information.
In the months leading up to the effective date of the Online News Act, then-Canadian Heritage Minister Pascale St-Onge urged the CRTC to investigate Meta’s decision to block news links on its Facebook and Instagram platforms as its method of compliance. Pointing to reports of people screenshotting news articles and the use of other workarounds the blocking of news links that came in response to the Online News Act (Bill C-18), St-Onge said “I cant wait to see what the CRTC will do when the law is fully enforced on Dec. 19.” As the law took effect and the issue grew, the CRTC did indeed send Meta a letter in October 2024 asking for information on how the company was complying with the legislation. I wrote about this request soon afterward, providing a detailed analysis of the law that sought to explain why some news sites might fall outside the scope of the legislation along with the legal grey area of screenshots.
This week, the CRTC finally responded to Meta on the issue. For the moment, it would appear that the Commission has no plans to take action. It states:
We are writing to advise that Commission staff have reviewed all the information submitted by Meta, while actively monitoring the situation. Commission staff has noted the steps that Meta has taken to implement and enforce its policies regarding news content. We will continue to monitor the situation and will follow up as needed.
In other words, there are no plans to take regulatory action against Meta. Given how the law was drafted, that is the right call. It has been clear for years that the companies captured by the legislation (Google and Meta) could comply by stopping to link to the news (Meta), negotiating some sort of payment deal (Google), or following the provisions for an arbitrated settlement (no one). The law was flawed from day one and the CRTC has apparently decided that more regulation that would undoubtedly end up being challenged in court was not going to fix it.
In 1888, Ainsworth Rand Spofford, the sixth Librarian of Congress, detailed his vision for the public reading room in the new Congressional Library — now known as the Thomas Jefferson Building. The space should follow the example set by the British Museum Library and be “circular or octagonal in form, so that all parts of it may be commanded” from the center.
To realize this panopticon concept, Spofford provided specifications for a “massive circular desk” that would give librarians and the Main Reading Room superintendent a view of every researcher, the card catalog and each alcove representing a major realm of knowledge.
Meanwhile, from the eye of the room’s domed ceiling, the figures in the aptly named painting “Human Understanding” could monitor the books springing forth from conveyor systems that connected the control room under the central desk to the stacks, the Capitol and eventually the John Adams Building and beyond. In her memoir “Thirty Years in Washington” (1901), Mary Cunningham Logan, the widow of Sen. John A. Logan, called the entire process — identifying, requesting and delivering books — a “marvel of ingenuity.”
The Library’s Main Reading Room as seen from high above. Photo: Shawn Miller.
Since that observation, the ingenious process has changed. The computer catalog replaced the card catalog; Electronic Book Paging phased out the call slips sent by pneumatic tubes; the book carrier pulled by continuously moving chains ceased operation, as did its replacement — a specialized elevator that lifted books from the control room into the reading room.
The tunnel to the Capitol, which once allowed the quick transport of materials to members of Congress, closed prior to the construction of the Capitol Visitor Center. And, the Library began providing content online, allowing researchers all over the world to access its digitized collections. Still, the mahogany central desk remains a powerful symbol — a direct connection between knowledge and its seekers and the never-ending quest to deepen and expand all human understanding.
The acquisition was announced this morning. The full text of the announcement is found below and is also available here.
Impelsys, a global technology services company, today announced the acquisition of Delta Think, a leading consultancy in scholarly communications. Together, the two companies will offer clients a powerful combination of strategy and technology expertise across publishing, education, and healthcare.
Since 2005, Delta Think has partnered with publishers, associations, and service providers to navigate change, understand their markets, and develop strategies for growth. Impelsys has been a trusted technology partner for more than two decades, helping organizations manage digital transformation and the accelerating shift toward AI. The company was an early pioneer in digital publishing, and its AI-enabled mon’k platform supports adaptive learning and digital content delivery for clients worldwide.
Together, Impelsys and Delta Think form a full-stack partner that can advise on business strategy and deliver technology execution at scale. Both organizations have deep, trusted partnerships with the clients they serve, and that commitment remains central as they move forward together.
“This is our first acquisition and a meaningful step in shaping the next chapter of Impelsys,” said Sameer Shariff, CEO of Impelsys. “Bringing Delta Think into the Impelsys family expands our capabilities in ways that matter and reflects our commitment to investing, both organically and through future acquisitions, to help our clients advance their digital and AI ambitions.”
“Delta Think was built for guiding clients to a deeper understanding of their markets, developing solutions built on evidence, and moving forward with confidence grounded in insight,” said Bonnie Gruber, Managing Director. “Joining Impelsys allows us to continue that same dedication and commitment while offering even broader solutions, expanding our global scale, and ensuring we continue to provide the level of innovative results our clients have come to expect from us,” added Lori Carlin, Chief Commercial Officer.
Delta Think will continue to operate under its own brand, with its leadership and team in place, now complemented by the expanded expertise and reach of Impelsys
Today, we are pleased to release The Public Interest Corpus Principles and Goals. This release builds on the recap of our final planning workshop and anticipates release of our final deliverable later this month.
[Clip]
The Public Interest Corpus works with a growing coalition of stakeholders to develop a service that advances the library community’s ability to support the responsible use of their collections for AI research and development and computational research more generally. The initial focus of the service is on a corpus development, discovery, and access solution for books data (digitized and/or born digital text with metadata) at scale. Some estimatessuggest that ~162,000,000 books have been created globally, with ~2,200,000 new books published each year. Collectively, libraries steward the most comprehensive source of human inquiry recorded in book form.
[Clip]
What principles guide The Public Interest Corpus?
The Public Interest Corpus … advances equitable access to books data for small, medium, and large organizations.
The Public Interest Corpus … supports AI research and developmentand computational research that addresses public interest challenges (e.g., fighting misinformation, advancing understanding of the past and present, fostering a more informed citizenry).
The Public Interest Corpus … addresses corpus limitations (e.g., linguistic bias, outmoded forms of knowledge present in the corpus, and data quality) through production of additional metadata in line with efforts like the Hugging Face Model Card and Data Nutrition Label.
The Public Interest Corpus … commits to transparency with respect to corpus composition, modification, and agreements in order to increase public trust in research that makes use of the corpus.
The Public Interest Corpus … values the labor of content creators and works to ensure that their work is recognized through promotion of credit and attribution practices.
The Public Interest Corpus … adopts practices and infrastructure that aim to reduce the environmental impactof corpus development, discovery, and access.
The Public Interest Corpus … forms partnerships that concretely address long-term collective needs of academic libraries and the communities they serve (e.g., maximizing access, reducing legal encumbrances).
The Public Interest Corpus … is fundamentally guided by diverse stakeholders including but not limited to researchers, librarians, publishers, authors, and technologists.
What goals should The Public Interest Corpus work to achieve?
Coordinate books data sourcing, discovery, and access across small, medium, and large organizations.
Create cost efficiencies in access to books data.
Minimize legal risk for those that seek to provide or make use of books data.
Curate and provideaccess to fit-for-purpose books data that exceeds in quality and comprehensiveness what is otherwise available.
Ensure consistent corpus growth and refinement over time in alignment with user community needs.
Identify and adopt scalable author credit and attribution methods for authors and rights holders to track reuse.
Deliver minimum viable solutions.
Adopt a fit for purpose governance model.
Develop a sustainability model that reduces barriers to books data access for small, medium, and large organizations on an ongoing basis.
Spoiler: the nine-person team works for Anthropic. People’s jobs, their brains, their democratic election process, their ability to connect with others emotionally — all of it...
The Writing Is on the Wall for Handwriting Recognition At this point, AI tools like Gemini should be able to make most digitized handwritten documents searchable...
A nationwide internet age verification plan is sweeping Congress The bill is set to be discussed in a hearing before a powerful House committee that’s considering...
A former middle school administrator in the Elizabeth School District filed a lawsuit Sunday against the rural Colorado district, alleging that she was fired after she objected to the removal of 19 titles from school libraries last year.
LeEllen Condry, who served as dean of students at Elizabeth Middle School, said she was terminated after three months because she’s “a Black woman who dared to speak out against the discriminatory book ban,” according to the lawsuit.
The lawsuit, filed in federal district court, alleges that the school district violated Condry’s free speech rights and discriminated against her based on race and sex.
Earlier this year, the American Civil Liberties Union (ACLU) sued ESD for removing the books from the libraries, and a federal judge ordered ESD to bring the banned books back on the shelves. Denver7 listened to a former ESD educator who said this decision “isn’t taking anything away from parents, but it’s giving a lot back to the kids.”
[Clip]
“The main point of doing this is that no person should be fired for speaking out against something that’s wrong,” said Condry.” For example, no books should be removed. No books should be on a sensitive list. We are all here to grow and learn from each other, and that’s key to our growth as people.”
In an August 2024 email to staff, the superintendent, Dan Snowberger, described the board’s responsibility to respond to the voters of the “very conservative community.”
“Our parents, though they may see things differently than you, are not ignorant, uneducated, or racist. They simply have different points of view than you may have. Yes, there are some in our community who may disagree with the majority of Elbert County residents as a whole. We live in a very conservative community and must recognize our board’s charge is to respond to the community that elected them and holds them accountable,” Snowberger wrote.
[Clip]
“The Elizabeth School District has sought to silence the voices of Black women within the walls of its schools. It has done so through the imposition of a Book Ban prohibiting literary works that speak to the Black experience from its school library shelves,” the lawsuit claims.
According to the lawsuit, after Condry sent her letter disapproving of the district’s decision, she and other district employees received an email from Snowberger saying that some of the feedback on the decision “crossed the lines of professional and ethical behavior.”
Condry is requesting economic and compensatory damages, a written apology and mandatory training for the district and other forms of relief.
At the lawsuit’s core is a list of 19 books removed from school libraries.
They included “#Pride: Championing LGBTQ Rights” by Rebecca Felix, “The Hate U Give” by Angie Thomas and “Thirteen Reasons Why” by Jay Asher.
[Clip]
Condry was terminated on Oct. 1, 2024, with Snowberger referencing “budgetary reasons” as the cause for her dismissal.
A month later, Condry was replaced by “a White woman who had no prior experience in the role” but who supported the book ban, according to the lawsuit.
Along with damages, including punitive damages, Condry is seeking a formal apology and the imposition of mandatory districtwide training.
“The district intends to defend itself in court, and the facts will show that the individual’s employment ended because she failed to take the steps to secure the necessary licensure for the position, and because the position was one of several eliminated for cost-saving reasons during a fiscal exigency,” Snowberger said.
The Journal of Academic Librarianship Volume 52, Issue 1, January 2026, 103162
DOI: 10.1016/j.acalib.2025.103162
Abstract
In the United States, book clubs are typically associated with the work of public or school librarians, due to their focus on extracurricular programs and recreational reading. However, published case studies and institutional websites indicate that book club programs are also taking place in academic libraries, though there is a lack of broad research investigating this topic further. This paper reports on a summer 2024 survey of US academic library workers who have facilitated book club programming. This study’s purposes were to determine the prevalence of book club programming in academic libraries and to identify successes, challenges, and trends in hosting these programs in academic contexts. The results of the survey provide insight into institutional trends, as well as possible benefits of book club programming in academic libraries, such as enhanced collaboration across campus, increased student retention, and a focus on diversity and inclusivity, and challenges, such as funding, staffing, and attendance. The survey results help to identify best practices for hosting engaging and accessible book club programs for various audiences in the academic library.
OpenAI desperate to avoid explaining why it deleted pirated book datasets But the authors suspect there’s more to the story than that. They noted that OpenAI...
His name was Robert Louis Stevenson, it was 1881 and he was playing a game with his stepson when he sketched out an idea.
“I made the map of an island; it was elaborately and (I thought) beautifully colored; the shape of it took my fancy beyond expression; it contained harbors that pleased me like sonnets; and, with the unconsciousness of the predestined, I ticketed my performance ‘Treasure Island,’ ” he wrote years later. “… The next thing I knew, I had some papers before me and was writing out a list of chapters.”
The center section of Robert Louis Stevenson’s “Treasure Island” map, with landmarks named and outlined. Rare Book and Special Collections Division.
“Treasure Island,” the adventurous story of a boy, gnarly pirates and a treasure map, would become one of the most influential novels of the era. Stevenson’s sketch has become one of the most famous literary maps in world literature.
After all, what would “The Lord of the Rings” be without its map of Middle-earth? If 18th-century readers of “Gulliver’s Travels” didn’t have a map to go along with Jonathan Swift’s satirical prose, how would they know where the fictional island of Lilliput — with its diminutive citizens — could be found? What sense could kids have made of “The Phantom Tollbooth” without legendary artist Jules Feiffer’s map of The Lands Beyond?
Here on a table in the soft light of the Rare Book and Special Collections Division is a first edition of William Faulkner’s “Absalom, Absalom!” with a foldout map of his fictional Yoknapatawpha County, Mississippi, the setting for most of the Nobel laureate’s work. Faulkner sketched it out himself. Just to the east of the “Pine Hills” area and just north of the squiggly river that gives the place its name, he wrote, “William Faulkner, sole owner and proprietor.”
William Faulkner sketched out a map of his fictional Yoknapatawpha County, Mississippi, at his publisher’s request. In this closeup, he identifies himself as the “sole owner and proprietor.” Rare Book and Special Collections Division.
There’s also a brisk post-publication demand for maps that show readers where authors lived and worked, or the places in which their characters came to life. This begins with the foundations of Western literature — Odysseus’ epic 10-year trip home after the Trojan War — and continues today, more than 2,700 years later.Name a famous fictional work and there’s a map showing you the highlights — Count Dracula came this way, Mrs. Dalloway went shopping here, the Buendia family lived there, James Bond got in trouble in all these places.
In “The Phantom Tollbooth,” artist Jules Feiffer sketched out the Sea of Knowledge. Rare Book and Special Collections Division.
This appeal isn’t hard to understand, says bestselling novelist Ace Atkins, who will receive the 2026 Harper Lee Award next year in his home state of Alabama.
Two decades ago, when he settled in Oxford, Mississippi, not far from Faulkner’s home, he had an idea for a series of books set in a fictional Mississippi county, similar to Faulkner’s. So, before he wrote a word of what turned out to be an 11-book series, he got a ruler, a manila folder, a glass of bourbon and started drawing a map of his new creation. Streets, stores, woods, the whole shebang. He included several shoutouts to Faulkner characters so readers would understand the homage.
“That’s the fun of it, just having a county like that and developing new rivers and creeks and places where events happened,” he said. “That map became much more alive as I continued to write the books.”
The CRTC recently released its much anticipated decision on Canadian content rules, the first of two decisions that could reshape broadcasting and film/TV production in Canada. The Commission promoted its Cancon approach as offering new flexibility into the system but the fine print matters as some changes may be more restrictive than they appear at first glance. To help make sense of the decision, Len St-Aubin, the former Director General of Telecommunications Policy at Industry Canada, joins the Law Bytes podcast. Len provided consulting services to Netflix until 2020 and has since been an active participant in the debate on Internet policy as part of the Canadian Internet Society.
After three days of voting in which more than 30,000 people had their say, we have chosen rage bait as our official Oxford Word of the Year for 2025.
With 2025’s news cycle dominated by social unrest, debates about the regulation of online content, and concerns over digital wellbeing, our experts noticed that the use of rage bait this year has evolved to signal a deeper shift in how we talk about attention—both how it is given and how it is sought after—engagement, and ethics online.
The word has also increased threefold in usage in the last 12 months, according to our language data.
We’re not rage baiting you by choosing two words—though that would be in keeping with the meaning of the term!
The Oxford Word of the Year can be a singular word or expression, which our lexicographers think of as a single unit of meaning.
Rage bait is a compound of the words rage, meaning a violent outburst of anger, and bait, an attractive morsel of food. Both terms are well-established in English and date back to Middle English times. Although a close parallel to the etymologically related clickbait, rage bait has a more specific focus on evoking anger, discord, and polarization.
The emergence of rage bait as a standalone term highlights both the flexibility of the English language, where two established words can be combined to give a more specific meaning in a particular context (in this case, online) and come together to create a term that resonates with the world we live in today.
Rage bait was first used online in a posting on Usenet in 2002 as a way to designate a particular type of driver reaction to being flashed at by another driver requesting to pass them, introducing the idea of deliberate agitation. The word then evolved into internet slang used to describe viral tweets, often to critique entire networks of content that determine what is posted online, like platforms, creators, and trends.
Since then, it has become shorthand for content designed to elicit anger by being frustrating, offensive, or deliberately divisive in nature, and a mainstream term referenced in newsrooms across the world and discourse amongst content creators. It’s also a proven tactic to drive engagement, commonly seen in performative politics. As social media algorithms began to reward more provocative content, this has developed into practices such as rage-farming, which is a more consistently applied attempt to manipulate reactions and to build anger and engagement over time by seeding content with rage bait, particularly in the form of deliberate misinformation of conspiracy theory-based material.
Isn’t rage bait two words?
The Oxford Word of the Year can be a singular word or expression, which our lexicographers think of as a single unit of meaning.
Rage bait is a compound of the words rage, meaning ‘a violent outburst of anger’, and bait, ‘an attractive morsel of food’. Both terms are well-established in English and date back to Middle English times. Although a close parallel to the etymologically related clickbait—which has a shared objective of encouraging online engagement and the potential to elicit annoyance—rage bait has a more specific focus on evoking anger, discord and polarization.
In honor of National Hispanic Heritage Month, which was celebrated from September 15 to October 15, the Latin American, Caribbean, and European Division (LACE) has released a new batch of unpublished recordings from the PALABRA Archive for online streaming.
The PALABRA Archive is a collection of audio recordings of 20th and 21st century poets and writers from Luso-Hispanic and U.S. Latino communities reading from their works. The collection now has now close to 900 recordings and continues to grow with new recordings by contemporary authors. Adding in the audios from this release, close to 650 recordings from this repository will be available digitally.
[Clip]
The newly released batch includes sessions both from the early years of the archive (1950s and 60s) to those recorded more recently. It highlights authors from sixteen countries with a special focus on Spain, including recordings that were done during a recording trip to Madrid and Barcelona in 2018. These include recordings with the late Almudena Grandes, one of Spain’s towering figures and the author of Las edades de Lulú (1989) (The Ages of Lulu); the novelist and journalist Rosa Montero; award-winning poet Luis García Montero, and the prominent Catalan authors Jaume Cabré and Carme Riera.
[Clip]
Click here to see the complete list of newly available recordings. We hope you enjoy our new digital treasures!
This report presents a brief overview of the socio-political landscape for scholarly communications and describes some of the major forces that could significantly impact the repository ecosystem in the coming years. The aim is to provide COAR members with a synopsis of current trends that may affect repositories as well as to inform the development of the next COAR Strategy to be published in December 2025.
The analysis was developed based on input from a survey of COAR members that took place in August/September 2025, a review of the literature and consultations with experts in the scholarly communications space, as well as feedback from the COAR Executive Board. COAR sincerely thanks everyone for their extremely valuable input in developing this document and in helping us to craft a more effective organisational strategy for the next three years.
As part of this analysis, we have identified several evolving and potentially volatile forces that are likely to have a significant impact on scholarly communications, open science, and repositories over the next three years. The report goes on to discuss the implications for repositories as a result of these forces.
Ewan is a new read for me......but he won't be the last! He describes his work as "I write nerve-shredding thrillers about ordinary situations gone wrong -- the kind of thing that could happen to any of us! I don't know if there is a name for this style - but I really like it!
In this novel, Ben and his partner, are caught up in bad weather. Here's the thing...would you let a woman, man and their baby in your car? On a back, dark, wet road. Abi has something she needs to tell Ben. He's got a kind heart...and that's all I'm going to give you.
I love the quick turns of the plot. The characters will change their behavior as well. Enjoy!
The U.S. Supreme Court postponed on Wednesday a decision on whether to let Donald Trump remove the government’s top copyright official, leaving her in place for now in the latest battle over the Republican president’s targeting of federal officials.
The justices declined to immediately resolve the Justice Department’s request to lift a lower court’s ruling that had blocked Trump’s firing of Shira Perlmutter as the U.S. register of copyrights and U.S. Copyright Office director while her legal challenge to her removal proceeds.
Justice Clarence Thomas said he would have allowed Perlmutter to be fired as her lawsuit proceeds. The court majority, though, decided to wait to make a decision until after they rule in two other lawsuits over Trump firings.
The present dispute began on May 10, one day after the Copyright Office released a pre-publication version of a report on artificial intelligence that made recommendations with which Trump allegedly disagreed. Perlmutter, whose position is known as the Register of Copyrights, received an email from the White House Presidential Personnel Office notifying her that she had been fired, “effective immediately.”
Perlmutter urged the justices to leave the D.C. Circuit’s order in place. The Library of Congress, she contended, is not an “executive agency.” To the contrary, she argued, the D.C. Circuit has already said, in a different case, that it is not, and “Congress has elsewhere regulated the Library as part of the legislative branch.” Therefore, she wrote, the president did not have the power to fire Hayden and appoint Blanche. And if Blanche was not validly appointed, Perlmutter continued, he did not have the power to fire her.
Last night I finished The Once and Future Kingby T.H. White, because I felt like it was time I made a real foray into the Arthurian legends. The actual first Arthurian book I read was The Mists of Avalon, but that was years ago and before I had heard the full story about Marion Zimmer Bradley. This book takes a decidedly different tone. I’m sticking to the most common name spellings for all of the characters here, because spellings do vary across all versions of these legends.
The first thing that surprised me about The Once and Future King is that it’s funny, and frequently in an absurd, dorky kind of way. Knights failing tilts because their visors fell over their eyes wrong, Merlin accidentally zapping himself away in the middle of a lesson because he was in a temper, the Questing Beast “falling in love” with two men dressed in a beast costume, that sort of thing. This silliness is largely concentrated in the first quarter of the book, which is about Arthur’s childhood, but it’s never fully lost.
The second surprise was how long the book focuses on Arthur’s childhood, but then again, it is setting the scene for Arthur’s worldview and the lessons he internalized as a child which shape his approach to being king.
—This is a guest post by Adam Guettel, the Tony Award-winning composer and lyricist of “The Light in the Piazza,” “Floyd Collins” and “Days of Wine and Roses.” It also appears in the September-October issue of the Library of Congress Magazine, which was primarily devoted to the arrival of Sondheim’s collection at the Library.
Stephen Sondheim died on November 26, 2021, relaxing into the arms of his husband, Jeff. What a triumph of a life, and what an exit.
The thing is, I hadn’t realized Steve was gone until just now. Maybe that’s because he’s not gone. He’s still here. And let me say right off, he wasn’t my mentor or advisor in a consistent way. His advice was sporadic, but indelible. I think I remember everything he ever said to me about music or writing for the theater.
One of Steve’s great inventions, among many, was his phrasing. He broke from the long, lyrical lines of Kern, Rodgers, Gershwin and Porter. He divided melody into conversational clauses, as Stravinsky divided folk melodies into cells in “L’Histoire du Soldat,” “Les Noces” and “Le Sacre du Printemps.”
Fifty years apart, they shocked and insulted music and theater conservatives in Europe and New York with the same profound insight: that melody could be pixelated and recombined into something original and dynamic. What a blessing that this migration can be charted in the Sondheim Collection and the rich collection of Stravinsky manuscripts in the Library.
And there is the Steve I knew as a person. (So much has been thoughtfully written about his work.) Many were intimidated by him. But for a man at the pinnacle of the arts, he was a social journeyman; rumpled, shy, easily embarrassed, warm, generous, easily offended and quick to forgive. Doing his best. People probably thought Beethoven was grouchy, too.
Once, I brought Steve to Wempe, an elegant watch boutique on 5th Avenue, thinking he might be drawn to a beautiful watch, where less was more, and content dictated form, and God was in the details. He politely turned them all down. On the way to lunch, he said he didn’t understand spending so much on something that did so little. Sort of like the opposite of clarity.
On my piano rests one of Steve’s planetary watches, an orrery. It’s made of metal, beautiful and precise. That’s his level of interest, way up there, his level of endeavor, and now he circles around us, a giant in the sky. He’ll always be a giant here, too, thanks to the Library of Congress. He will never be gone. We can know him, and ask him and have him forever.
By age